
 自動化のプロあお
自動化のプロあお2025/12/18のAIニュースをまとめました!
本日は、今年2025年12月に発表されたばかりの最新AIモデルに関するニュースを厳選してご紹介します。
OpenAIやGoogle、Meta、Xiaomiなど、業界をリードする企業が発表したAIモデルの進化や自動化の最前線を一気にチェックできます。
AI自動化の最新トレンドや、今後のビジネス・開発現場への影響を知りたい方は必見です。
- OpenAIがGPT-5.2を発表し性能大幅強化
- Metaが音源編集AI「SAM Audio」をリリース
- ChatGPT Images 1.5で画像生成速度4倍化
- Googleが高速処理AI「Gemini 3 Flash」公開
- XiaomiがMiMo-V2-Flashを高速・低コストで発表
ニュース1:OpenAIがGPT-5.2を発表し性能大幅強化

- GPT-5.2は2025年12月に発表された最新AIモデル
- 知識カットオフが2025年8月まで拡大し実務性能が大幅向上
- 推論設定や長文処理、コスト効率が大きく進化
GPT-5.2は2025年12月に発表された最新AIモデルで、OpenAIのフラグシップとして注目を集めています。
今回のGPT-5.2は知識カットオフが2025年8月まで拡大し実務性能が大幅向上した点が大きな特徴です。
用途別にInstant、Thinking、Proの3ラインが用意され、推論設定や長文処理、コスト効率が大きく進化しています。
最大256kトークンの長文コンテキスト対応により、ビジネス書数冊分の情報も一度に処理可能となりました。
実務性能指標GDPvalでは人間専門家と同等以上の割合が70.9%に達し、業務自動化の信頼性が大きく向上しています。
特定業務では人間の11倍以上の速度、コスト1%未満でタスクを完了できる点も大きな進化です。
ハルシネーション(事実誤認)も約30〜38%削減され、ビジネス利用時のリスクが低減しています。
長時間エージェントやマルチモーダル処理も強化され、AI自動化の幅がさらに広がりました。
今後はAPIや各種サービスへの導入が進み、AIによる知識労働の自動化が加速する見通しです。
| サービス名 | GPT-5.2シリーズ |
|---|---|
| 発表日・モデル位置付け | 2025年12月11日発表の最新フラグシップ |
| 主なラインナップ | Instant / Thinking / Proの3ライン |
| 知識カットオフ | 2025年8月まで対応 |
| 最大コンテキスト長 | 256kトークン(約35万〜45万字) |
| 推論設定(Thinking Mode) | none / low / medium / high / xhighの5段階 |
| 実務性能指標(GDPval) | 人間専門家同等以上が70.9% |
| 速度・コスト | 人間の11倍以上の速度、コスト1%未満 |
| ハルシネーション低減率 | 約30〜38%削減 |
| 提供プラン・API対応 | ChatGPT有料プラン・API同時公開 |
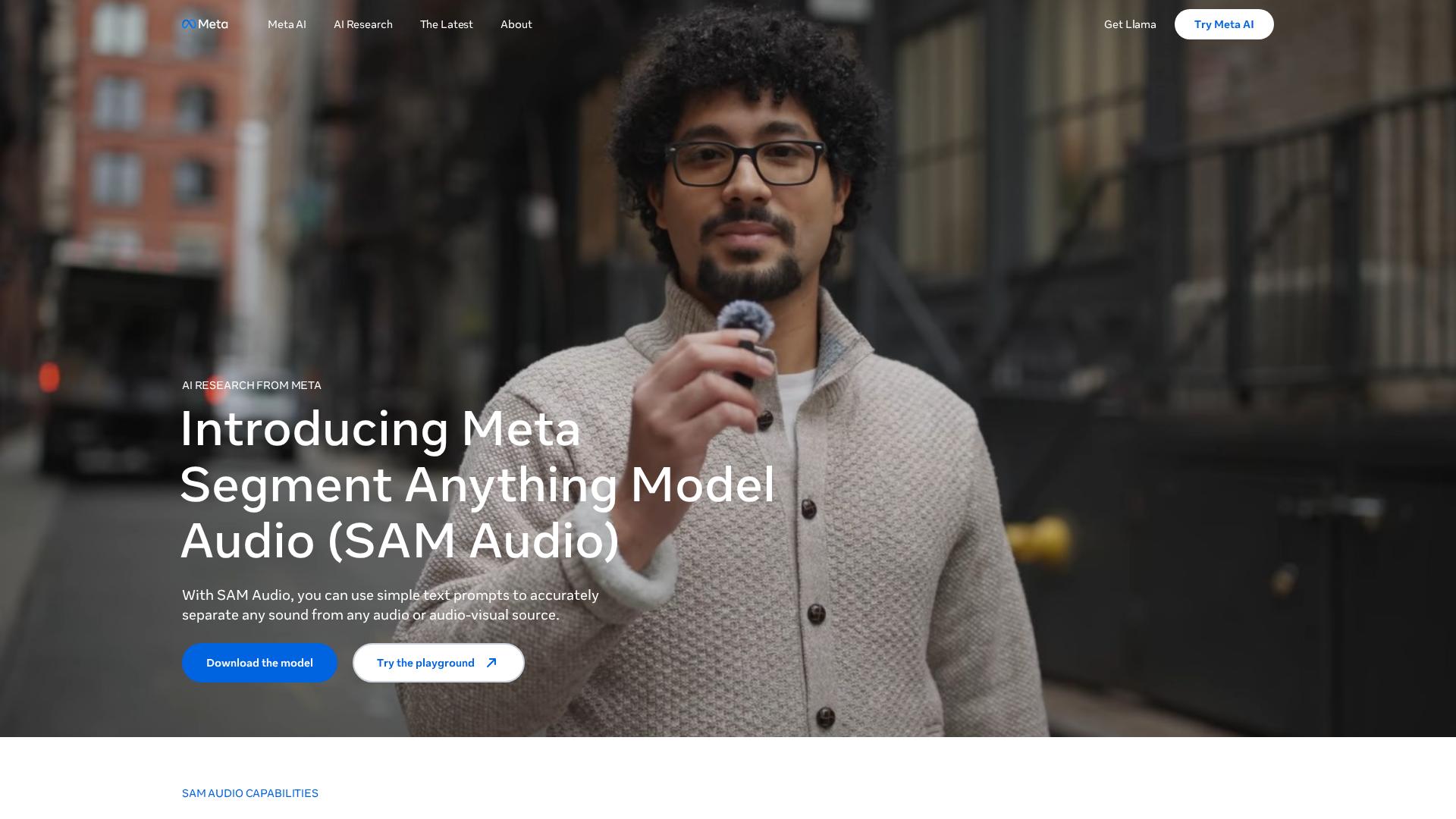
ニュース2:Metaが音源編集AI「SAM Audio」をリリース
- MetaがSAM Audioを2025年12月に正式リリース
- テキストや映像クリックで直感的に音分離
- 音楽制作や動画編集など多様な現場で活用
- 単一モデルで従来AIを上回る分離性能を実現
- Hugging FaceやGitHubでオープン提供開始
- 音声編集の民主化と著作権課題が注目点
MetaがSAM Audioを2025年12月に正式リリースし、音声編集AI分野に新たなスタンダードを打ち立てました。
テキストや映像クリックで直感的に音分離できるため、専門知識がなくても高度な音源抽出が可能です。
音楽制作や動画編集など多様な現場で活用され、作業効率化やクリエイティブの幅を大きく広げます。
単一モデルで従来AIを上回る分離性能を実現し、ノイズ除去や特定音声抽出の精度が大幅に向上しています。
Hugging FaceやGitHubでオープン提供開始され、開発者やクリエイターがすぐに試せる環境が整いました。
音声編集の民主化と著作権課題が注目点となり、今後の音声・映像制作の在り方にも大きな影響を与えそうです。
| サービス名 | SAM Audio(Segment Anything Model for Audio) |
|---|---|
| 提供元 | Meta |
| 主な特徴 | 音声・映像から任意の音を分離できる統合マルチモーダルAI |
| 入力方法 | テキスト指定/ビジュアル指定(動画内クリック)/時間領域指定/マルチモーダル(音声・動画) |
| 代表的な利用シーン | 音楽制作・ミキシング、動画編集、ポッドキャスト、研究・アクセシビリティ |
| 技術的特徴 | 単一モデルで多様な音源分離に対応、従来AIを上回るベンチマーク性能 |
| 提供形態 | オープン提供(Hugging Face、GitHub、Webプレイグラウンド) |
| 社会的インパクト | 音声編集の民主化、著作権・二次利用の課題 |
| 公式サイト | https://ai.meta.com/samaudio/ |
ニュース3:OpenAIがChatGPT Images 1.5で生成速度4倍化
- ChatGPT Images 1.5が画像生成速度を最大4倍に高速化
- 新たに画像メニュー追加や即時生成機能を搭載
- APIコスト20%低減し無料ユーザーも利用可能に
ChatGPT Images 1.5が画像生成速度を最大4倍に高速化したことで、業務やクリエイティブ用途の自動化がさらに進みます。
今回のアップデートでは新たに画像メニュー追加や即時生成機能を搭載し、直感的な操作性が大きく向上しました。
画像生成中でも新規生成が可能となり、作業効率が飛躍的にアップします。
API利用料金も20%低減し無料ユーザーも利用可能になったことで、幅広い層が手軽に画像生成AIを活用できます。
指示追従性や写真編集能力も強化され、より細かな要望に応えることが可能となりました。
高密度テキスト描画性能も向上し、新聞記事や表などの複雑な画像も正確に生成できます。
APIではinput_fidelityパラメータの追加で、顔やロゴなどのディテール保持も強化されています。
マーケティングやWeb制作現場でも、WixやCanvaなどのツールと連携しやすくなりました。
今後は多ターン編集やさらなる自然さの向上も予定されており、画像生成AIの進化が期待されます。
| サービス名 | ChatGPT Images 1.5 |
|---|---|
| リリース日 | 2025年12月17日(日本時間) |
| 主な特徴・改善点 | 生成速度4倍化、指示追従性・編集能力強化 |
| 新機能 | 画像メニュー追加、即時生成、生成中の新規生成 |
| 提供範囲 | 全ChatGPTユーザー・API利用者、順次拡大中 |
| API利用料金 | 従来比20%低減 |
| 画像生成速度 | 従来比最大4倍高速化 |
| 編集・カスタマイズ機能 | プリセットフィルター、トレンドプロンプト、input_fidelity |
| 対応プラットフォーム | Web、API、Wix/Canva等連携 |
ニュース4:Googleが高速処理AI「Gemini 3 Flash」を公開
- Gemini 3 FlashはGemini 3ファミリーの高速・低コスト特化モデル
- Gemini 2.5 Pro比で最大3倍の応答速度と30%少ないトークン消費
- API料金が大幅に低価格化され、無料利用範囲も拡大
- マルチモーダル理解と高いコーディング性能を維持
- ビジネス現場での自動化・高速エージェント活用が加速
Gemini 3 FlashはGemini 3ファミリーの高速・低コスト特化モデルとして、2025年12月17日に正式発表されました。
Gemini 2.5 Pro比で最大3倍の応答速度と30%少ないトークン消費を実現し、日常業務や開発現場での大量処理に最適化されています。
API料金が大幅に低価格化され、無料利用範囲も拡大したことで、個人・法人問わず導入障壁が大きく下がりました。
マルチモーダル理解と高いコーディング性能を維持しつつ、レイテンシやコスト効率を徹底的に最適化しています。
ビジネス現場での自動化・高速エージェント活用が加速し、コーディング支援やカスタマーサポート、メディア業務の自動化が進んでいます。
Gemini 3 FlashはGoogle AI StudioやVertex AI、Geminiアプリなど多様なチャネルで利用可能です。
JetBrainsやFigmaなどの開発ツール、Salesforceなど業務SaaSにも組み込まれ、実サービスでの導入が拡大しています。
Gemini 3 FlashはGeminiアプリやGoogle検索AIモードのデフォルトモデルとなり、無料ユーザーも高性能AIを体験できます。
競合のGPT-5.2などと並び、2026年以降のAI自動化基盤として注目されています。
| サービス名 | Gemini 3 Flash |
|---|---|
| モデルの位置づけ | Gemini 3ファミリーの高速・低コスト特化モデル |
| 発表日 | 2025年12月17日 |
| 主な特徴(性能) | Gemini 2.5 Pro比で最大3倍の応答速度、平均30%少ないトークン消費、フロンティア級推論・コーディング性能 |
| 主な特徴(コスト・料金) | API入力100万トークン0.50ドル、出力100万トークン3ドル、無料利用範囲も拡大 |
| 主な特徴(技術・機能) | 高度なマルチモーダル理解、動的な思考深度調整、効率重視設計 |
| 利用可能なチャネル | Google AI Studio、Vertex AI、Geminiアプリ、Google検索AIモード、Android Studioなど |
| 主な活用例 | 高速エージェント、コーディング支援、カスタマーサポート、メディア業務、業務プロセス自動化 |
| 無料利用範囲 | Geminiアプリの無料ユーザーもデフォルトで利用可能 |
| 競合モデルとの違い | 速度・コスト効率に特化し、実サービス向けAI基盤として差別化 |
ニュース5:Xiaomiが高速・低コストAIモデルMiMo-V2-Flash発表

- MiMo-V2-Flashは3090億パラメータの高速LLM
- 推論コストはClaude 4.5 Sonnet比2.5%で圧倒的低価格
- 完全オープンソース化で企業のAI自動化を加速
MiMo-V2-Flashは3090億パラメータの高速LLMとして、Xiaomiが2025年12月に発表しました。
このモデルは推論速度約150トークン/秒を実現し、DeepSeek-V3.2級の性能を維持しつつレイテンシを大幅に低減しています。
推論コストはClaude 4.5 Sonnet比2.5%で圧倒的低価格となり、API利用時も1ドル未満/100万トークンの水準です。
アーキテクチャ面ではSliding Window AttentionとMTPで高速化を実現し、最大256Kトークンの超長文処理にも対応しています。
用途はAIエージェントやコード生成、業務自動化など多岐にわたり、企業や開発者の生産性向上に直結します。
完全オープンソース化で企業のAI自動化を加速し、MITライセンスで商用利用も自由です。
モデル重みや推論コードはGitHub・Hugging Faceで公開され、SGLangやTransformersでの自前運用も可能です。
ローカル実行時は量子化版で約180GB、VRAM15GB以上で動作し、RTX 3080以上が推奨されています。
無料トライアルはXiaomi MiMo StudioやOpenRouter経由で提供され、導入障壁が非常に低いのも特徴です。
中国勢のオープンAI戦略の中核として、低コストAI自動化のグローバル普及を後押しするモデルとなっています。
| サービス名 | MiMo-V2-Flash |
|---|---|
| モデル概要 | 3090億パラメータのMoE方式高速LLM |
| 主な用途・想定シナリオ | AIエージェント、コード生成、業務自動化 |
| 推論速度 | 約150トークン/秒(世界最速級) |
| 推論コスト・料金 | Claude 4.5 Sonnet比2.5%、APIは$0.1/百万トークン |
| 性能・ベンチマーク | DeepSeek-V3.2級、エージェント評価Top2、コード能力Claude 4.5 Sonnet級 |
| アーキテクチャ・技術特徴 | Sliding Window Attention、MTP、256K超長文対応 |
| オープンソース・ライセンス | MITライセンス、GitHub・Hugging Faceで公開 |
| 提供チャネル・無料トライアル | Xiaomi MiMo Studio、OpenRouter、SGLang対応、無料利用可 |
| ローカル実行・ハード要件 | 量子化版180GB、VRAM15GB以上、RTX 3080以上推奨 |
まとめ
自動化のプロあお本日のニュースはここまで!
2025年はAIモデルの進化が加速した一年でした。
OpenAIのGPT-5.2やGoogleのGemini 3 Flashなど、各社が高速・高性能なAIを発表しています。
MetaのSAM AudioやXiaomiのMiMo-V2-Flashも、音声・画像・言語分野で自動化を推進しています。
これらの進化により、ビジネスや日常生活でのAI活用が一層身近になりました。
今後もAI自動化の可能性はさらに広がると期待できます。
最新AIニュースを追い続けることで、未来の自動化社会を先取りしましょう。










